- root
- version of ubuntu/java
- how to add user in ubuntu
- how to delete user in ubuntu
- how to check the user's list in ubuntu
- how to distinguish local file system with distributed file system
- list out all the commands used in hadoop
- fsck
- hadoop version
- ls/lsr
- mkdir
- touchz / appendToFile
- copyFromLocal / put
- copyToLocal / get
- mv
- cp
- chown
- chgrp
- setrep
- du
- df
- stat
- help
- count
1. root:
How to check whether u r in root r not
id -u
2.version of ubuntu/java
How to know the version of ubuntu
lsb_release -a
How to know the java version of ubuntu
java -version;javac -version
3.add user:
How to add the user in ubuntu
sudo adduser usrk
4. delete user:
How to delete the user in ubuntu
sudo deluser usrk
but it is not going to delete the user in order to delete we use
sudo rm -r usrk
5.check:
How to check the userlist in ubuntuls /home/
6.local file system & Distributed file system :
How to know local file system commands used in hadoop
hduser@rk-virtual-machine:~$ ls
Distributed file system commands used in hadoop
hduser@rk-virtual-machine:~$ hdfs dfs -ls /
7.list out all the commands used in hadoop
How to know what are the commands used in hadoop
hadoop fs -help
hadoop fs
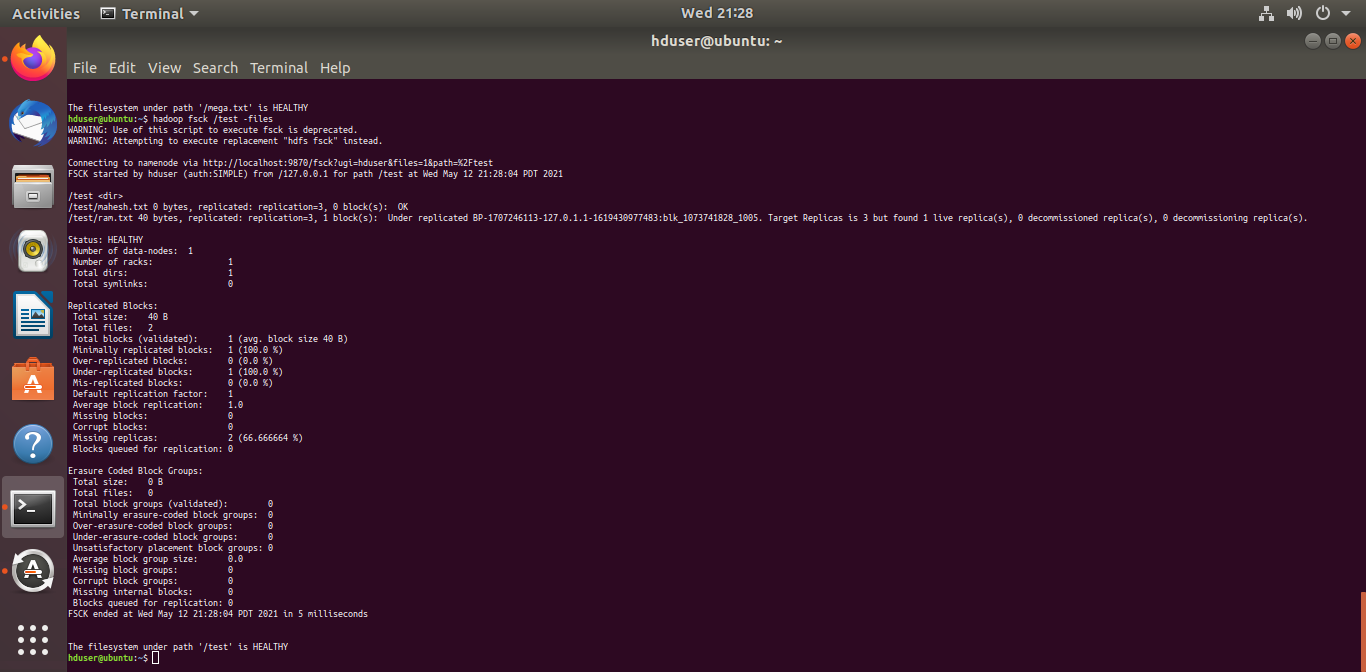
8.fsck:
How to check the file system check healthy r not
hdfs fsck /
or
hadoop fsck /
fsck:How to use fsck commands in hadoop :
In this example, we are trying to check the health of the files in ‘test’ directory present in HDFS using the fsck command.
Usage:hadoop fsck <path> [ -move | -delete | -openforwrite] [-files [-blocks [-locations | -racks]]]
9.hadoop version :
How to check the hadoop version
Usage: version
hadoop version
or
hdfs version
How to check hdfs / hadoop root Usage:hadoop fs -ls /path
hadoop fs -ls /
or
hdfs dfs -ls /
hadoop fs -lsr / OR hadoop fs -ls -R / or
hadoop fs -lsr / OR hdfs dfs -ls -R /
11. mkdir:
How to create directory in hadoopUsage:hadoop fs –mkdir /path/directory_name
hadoop fs -mkdir /test
or
hdfs dfs -mkdir /test
hadoop fs -mkdir -p /ram/sita OR hadoop fs -mkdir -p /ram/sita or
hadoop fs -mkdir -p /ram/sita OR hdfs dfs -mkdir -p /ram/sita

12. touchz / appendToFile:
How to create file ZERO BYTE FILE and NON ZERO BYTE FILE in hadoop
Usage:hadoop fs –touchz /directory/filename
1) hadoop fs -touchz /virat.txt ZERO BYTE FILE
or
hdfs dfs -touchz /virat.txt
2) hadoop fs -appendToFile - /dhoni.txt NON ZERO BYTE FILE
or hdfs dfs -appendToFile - /dhoni.txt
In this case you need to write some text
for example dhoni is a boy Ctrl + d

13. copyFromLocal / put:
How to create -copyFromLocal OR -put into hadoop (Local to Hadoop)
Usage:hadoop fs -copyFromLocal <localsrc> <hdfs destination>
1) hadoop fs -copyFromLocal tanmai.txt /chiru
or
hdfs dfs -copyFromLocal tanmai.txt /chiru
Usage:hadoop fs -put <localsrc> <hdfs destination>
2) hadoop fs -put sita.txt /chiru
or hdfs dfs -put sita.txt /chiru
Note:
In this case it puts the file sita.txt from local to hadoop for that you need to create a file in local file system first and then it should be copyFromLocal to distributed file system
14. copyToLocal / get:
How to create -copyToLocal OR -get from hadoop (Hadoop to Local)
Usage:hadoop fs -copyToLocal <hdfs source> <localdst>
1) hadoop fs -copyToLocal /chiru/tanmai.txt /home/hduser/ramcharan/
or
hdfs dfs -copyToLocal /chiru/tanmai.txt /home/hduser/ramcharan/
Usage:hadoop fs -get <hdfs source> <localdst>
2) hadoop fs -get /chiru/hari.txt /home/hduser/ramcharan/
or hdfs dfs -get /chiru/hari.txt /home/hduser/ramcharan/
Note:
In this case it puts the file hari.txt from hadoop to local for that you need to create a dummy directory (ramcharan)in local first and then it should be copyToLocal
15.mv:
How to use mv commands in hadoop The HDFS mv command moves the files or directories from the source to a destination within HDFS
Usage:hadoop fs -mv <src> <dest>
hadoop fs -mv /chiru/hari.txt /rohith/
or hdfs dfs -mv /chiru/hari.txt /rohith/
16. cp:
How to use cp commands in hadoop
The cp command copies a file from one directory to another directory within the HDFS.
Usage:hadoop fs -cp <src> <dest>
hadoop fs -cp /rohith/ram.txt /chiru/
or hdfs dfs -cp /rohith/ram.txt /chiru/
17. chown:How to use chown commands in hadoop :
Here we are changing the owner of a file name sample using the chown command.
Usage:hadoop fs -chown [-R] [owner] [:[group]] <path>
How to use chgrp commands in hadoop :
The Hadoop fs shell command chgrp changes the group of the file specified in the path.
The user must be the owner of the file or superuser.
Usage:hadoop fs -chgrp <group> <path>
19. setrep:
How to use setrep commands in hadoop :
Here we are trying to change the replication factor of the ‘ram.txt’ and 'mahesh.txt' file
present in test directory on the HDFS filesystem
Usage: hadoop fs -setrep <rep> <path>
20. du:
How to use du commands in hadoop :
This Hadoop fs shell command du prints a summary of the amount of disk usage of all files/directories in the path.
Usage:hadoop fs –du –s /directory/filename
hdfs dfs -du /chiru
hdfs dfs -du -s /chiru
21. df:How to use df commands in hadoop :
The Hadoop fs shell command df shows the capacity, size, and free space available on the HDFS file system.
The -h option formats the file size in the human-readable format.
Usage:hadoop fs -df [-h] <path>
How to use stat commands in hadoop :In the below example, we are using the stat command to print the information about file ‘mahesh.txt' present in the test directory of HDFS.
Usage: hadoop fs -stat [format] <path>
The Hadoop fs shell command stat prints the statistics about the file or directory in the specified format.
Formats:
%b – file size in bytes
%g – group name of owner
%n – file name
%o – block size
%r – replication
%u – user name of owner
%y – modification date
23. help:
How to use help commands in hadoop :
The Hadoop fs shell command help shows help for all the commands or the specified command.
Usage:hadoop fs -help [command]
24. count:
How to use count commands in hadoop :
Usage:hadoop fs -count [options] <path>
The Hadoop fs shell command count counts the number of files, directories, and bytes under the paths that matches the specified file pattern.
Options:
-q – shows quotas(quota is the hard limit on the number of names and amount of space used for individual directories)
-u – it limits output to show quotas and usage only
-h – shows sizes in a human-readable format
-v – shows header line
Access Hadoop UI from Browser:
Hadoop NameNode: Use your preferred browser and navigate to your localhost URL or IP. The default port number 9870 gives you access to the Hadoop NameNode UI:
http://localhost:9870
Hadoop DataNode: The default port 9864 is used to access individual DataNodes directly from your browser:
http://localhost:9864
YARN Resource Manager: The YARN Resource Manager is accessible on port 8088:
http://localhost:8088






























No comments:
Post a Comment