- Edit .bashrc file
- Edit hive-config.sh file
- Create Hive directories in HDFS
- Configure hive-site.xml file
- Initiate Derby database
Step 1: Download and Untar Hive
Download the compressed Hive files using wget
wget https://downloads.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gzOnce the download process is complete, untar the compressed Hive package:
tar xzf apache-hive-3.1.2-bin.tar.gzStep 2: Configure Hive Environment Variables (bashrc)
Edit the .bashrc shell configuration file using using nano
hduser@rk-virtual-machine:~$ nano .bashrc




Save and exit the .bashrc file once you add the Hivevariables.
hduser@rk-virtual-machine:~$ source ~/.bashrc Step 3: Edit hive-config.sh file
hduser@rk-virtual-machine:~$ cd apache-hive-3.1.2-bin/
hduser@rk-virtual-machine:~/apache-hive-3.1.2-bin$ cd bin
hduser@rk-virtual-machine:~/apache-hive-3.1.2-bin/bin$ ls




Step 4: Create Hive Directories in HDFS
Create two separate directories to store data in the HDFS layer:
- The temporary, tmp directory is going to store the intermediate results of Hive processes.
- The warehouse directory is going to store the Hive related tables
1.Create tmp Directory
Create a tmp directory within the HDFS storage layer. This directory is going to store the intermediary data Hive sends to the HDFS:
hdfs dfs -mkdir /tmpAdd write and execute permissions to tmp group members:
hdfs dfs -chmod g+w /tmpCheck if the permissions were added correctly:
hdfs dfs -ls /The output confirms that users now have write and execute permissions.

2.Create warehouse Directory
Create the warehouse directory within the /user/hive/ parent directory:
hdfs dfs -mkdir -p /user/hive/warehouseAdd write and execute permissions to warehouse group members:
hdfs dfs -chmod g+w /user/hive/warehouseCheck if the permissions were added correctly:
hdfs dfs -ls /user/hiveThe output confirms that users now have write and execute permissions.

Step 5: Configure hive-site.xml File (Optional)
Use the following command to locate the correct file:
hduser@rk-virtual-machine:~/apache-hive-3.1.2-bin$ cd conf/
Use the hive-default.xml.template to create the hive-site.xml file:
cp hive-default.xml.template hive-site.xmlAccess the hive-site.xml file using the nano text editor:
sudo nano hive-site.xml
hduser@rk-virtual-machine:~/apache-hive-3.1.2-bin$ cd conf/
cp hive-default.xml.template hive-site.xmlsudo nano hive-site.xml
add this file in the beginning <property>
<name>system:java.io.tmpdir</name>
<value>/tmp/hive/java</value>
</property>
<property>
<name>system:user.name</name>
<value>${user.name}</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:,databaseName=$HIVE_HOME/metastore_db;create=true</value>
<description>JDBC connect string for a JDBC metastore </description>
</property>
(OR) <property>
<name>system:java.io.tmpdir</name>
<value>/tmp/hive/java</value>
</property>
<property>
<name>system:user.name</name>
<value>${user.name}</value>
</property>
and add another file in middle as shown
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>




Note : After running the command schematool –initSchema –dbType derby we need to set guava jar as shown below then you need to open the file hive-site.xml and then we need identify the error usually the error may occur at 3224 line of the code you need to set by deleting the error and then run the command
schematool -initSchema -dbType derby
Step 6: Initiate Derby Database
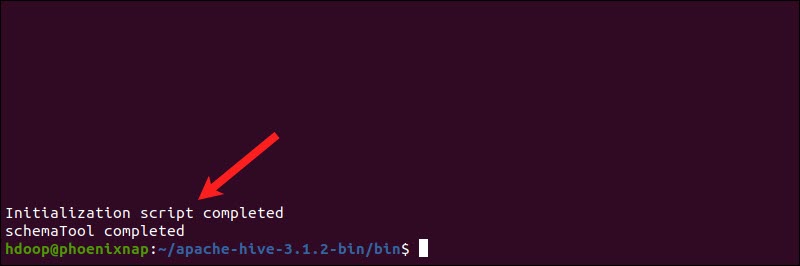
schematool command:hduser@rk-virtual-machine:~/apache-hive-3.1.2-bin/bin$ schematool -initSchema -dbType derby
The process can take a few moments to complete.
How to Fix guava Incompatibility Error in Hive
If the Derby database does not successfully initiate, you might receive an error with the following content:
“Exception in thread “main” java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V”
This error indicates that there is most likely an incompatibility issue between Hadoop and Hive guava versions.
Locate the guava jar file in the Hive lib directory:
ls $HIVE_HOME/lib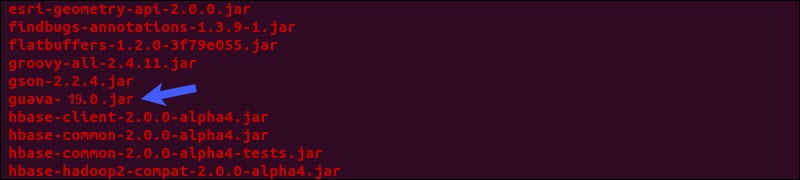
Locate the guava jar file in the Hadoop lib directory as well:
ls $HADOOP_HOME/share/hadoop/hdfs/lib
The two listed versions are not compatible and are causing the error. Remove the existing guava file from the Hive lib directory:
rm $HIVE_HOME/lib/guava-19.0.jarCopy the guava file from the Hadoop lib directory to the Hive lib directory:
cp $HADOOP_HOME/share/hadoop/hdfs/lib/guava-27.0-jre.jar $HIVE_HOME/lib/Use the schematool command once again to initiate the Derby database:
$HIVE_HOME/bin/schematool –initSchema –dbType derbyLaunch Hive Client Shell on Ubuntu
Start the Hive command-line interface using the following commands:
cd $HIVE_HOME/binhiveYou are now able to issue SQL-like commands and directly interact with HDFS.

HIVE Installation Screenshots on top of Hadoop











At the beginning add this code : 1.Put the following at the beginning of hive-site.xml
<property>
<name>system:java.io.tmpdir</name>
<value>/tmp/hive/java</value>
</property>
<property>
<name>system:user.name</name>
<value>${user.name}</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:,databaseName=$HIVE_HOME/metastore_db;create=true</value>
<description>JDBC connect string for a JDBC metastore </description>
</property>

At the middle add this code : <property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>

How to Fix guava Incompatibility Error in Hive:


 If Still error occurs then change the file hive-site.xml which is located at
If Still error occurs then change the file hive-site.xml which is located at 
ctrl +wctrl + t - go to line number 3224


Launch Hive Client Shell on Ubuntu:
if error occurs in installation of hive :
This error occurs when hive-shell started before metastore_db
service. To avoid this just delete or move your metastore_db
and try the below command.
$ mv metastore_db metastore_db.tmp
$ schematool -dbType derby -initSchema
$./bin/hive





No comments:
Post a Comment